|
Thinking In .NET A place to learn about C# and the .NET Platform by Larry O'Brien. But mostly the obligatory braindump cross-linking that characterizes the blogsphere. |
|
|
|
|||||
|
|
|||||
|
|
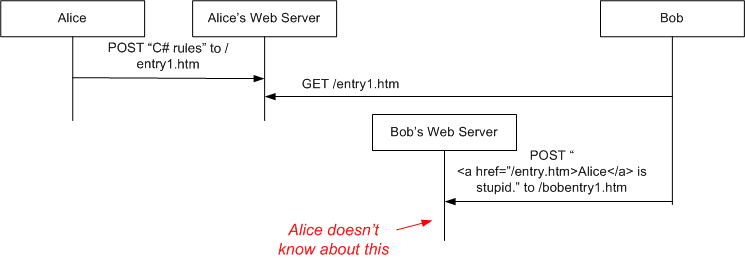
Pingback / Trackback vs. Referrer Logs Harvesting The problem: You want to know when someone has linked to your blog entry. If Alice posts a rant to her blog and Bob counters it on his, there is no basic way for Alice to know about Bob's response.
Since Alice may know nothing of Bob's Web Server, short of spidering the World Wide Web there's no way for her to know that Bob's Web Server contains a reference to her. So our task is to design a something that sits on her Web Server that figures out that Bob has written a response. That something needs two pieces of information: the URL to Alice's original post and the URL to Bob's response. Once the something has that information, it's a simple matter to regenerate Alice's original posting so that it now contains "Links referring to this page":
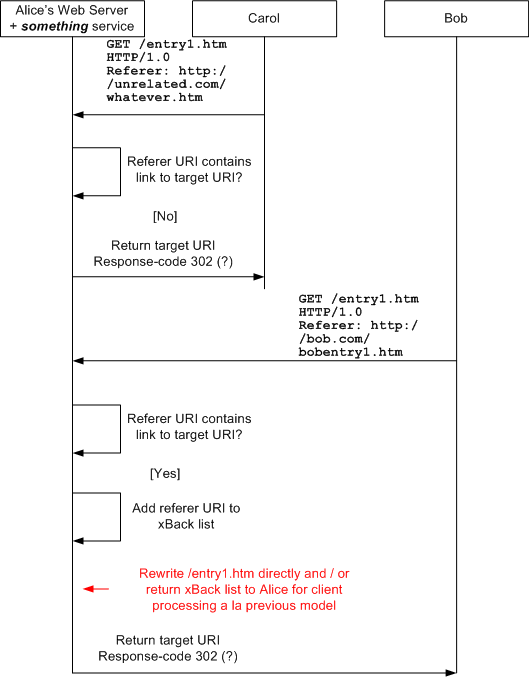
So one candidate for the something is something called a Trackback or Pingback server. In this solution, when Alice posts her original entry, she posts a URI to her xBack server: "alice.com/xBackServer?TargetUri=/entry1" and after Bob writes his post, he posts to the xBack server the fact that he has now posted a response: POST /alice.com/xBackServer?TargetUri="/entry1.htm"&ReferenceUri="http://bob/bobentry1.htm" Well, okay. That's one way to do it. But here are two other ways: The permalink to Alice's entry does not point to a simple Web page, but points to the something, which is a CGI / HttpHandler / servlet that reads the HTTP "referer" [sic] header and acts on that:
It seems to me that both of these latter designs are superior to the xBack design. The essential point being that the xBack design requires action on Bob's part aside from writing the post (he must "ping" the xBack server); the two "referer" designs discover Bob's post the first time someone follows the link from Bob's page to Alice's page. Bob should do that as soon as he posts the page, but in the xBack design, he must ping the xBack server. Even if Bob neglects / forgets to follow the link on posting, the referer designs will generate the cross-link the first time a reader traverses the link. The xBack design requires Bob to deal with two URIs (the target URI "alice.com/entry1.htm") and the xBack server URI ("alice.com/xback?targetUri="entry1.htm"), while the referer designs work with just the target URI. So I think the referer designs are preferable. Am I wrong? |